

杏彩体育图像生成、视频生成、整合语音合成的人脸动画、生成三维的人物运动以及 LLM 驱动的工具…… 一切都在这篇文章中。
生成式 AI 已经成为互联网的一个重要内容来源,现在你能看到 AI 生成的文本、代码、音频、图像以及视频和动画。今天我们要介绍的文章来自立陶宛博主和动画师 aulerius,其中按层级介绍和分类了动画领域使用的生成式 AI 技术,包括简要介绍、示例、优缺点以及相关工具。
他写道:「作为一位动画制作者,我希望一年前就有这样一份资源,那时候我只能在混乱的互联网上自行寻找可能性和不断出现的进展。」
本文的目标读者是任何对这一领域感兴趣的人,尤其是不知如何应对 AI 领域新技术发展的动画师和创意人士。另需说明,视频风格化虽然也是相关技术,但本文基本不会涉及这方面。
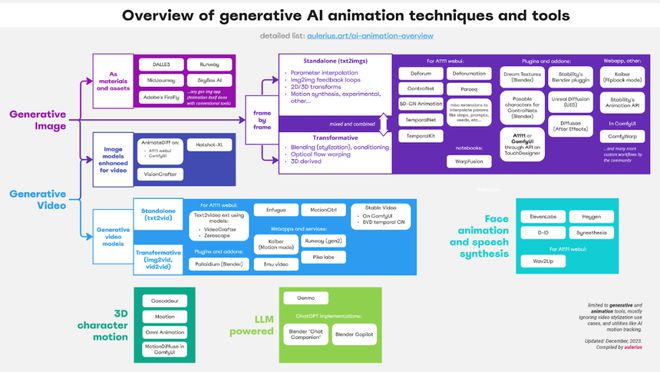
将任意 AI 应用生成的静态图像用作 2D 剪贴画、数字处理、拼贴等传统工作流程中的素材,或者用作 AI 工具的资源,比如提供给图像转视频(image2video)工具来生成视频。除了作为图像和素材来源,这类技术还需依赖剪切和图像编辑等一些常用技能。

短片《Planets and Robots》中使用了数字剪贴画来将生成的 AI 图像动画化,其中的配音也是使用 LLM 基于脚本生成的。
这类技术是以一种相当程度上立足动画根源的精神来使用生成式扩散图像模型,其是以逐帧方式生成动作序列,就像是传统动画制作的绘制再拍摄过程。其中的一大关键是这些模型在生成每张图像时没有时间或运动的概念,而是通过某种机制或各种应用或扩展来帮助得到某种程度上的动画,从而实现所谓的「时间一致性(temporal consistency)」。
这些技术得到的动画往往会出现闪烁现象。尽管许多使用这些工具的用户会努力清理这些闪烁,但动画师却会把这视为一种艺术形式,称为 boiling。
这方面最常用的是 Stable Diffusion 等开源模型以及基于它们构建的工具。用户可以使用公开的参数来配置它们,还可以将它们运行在本地计算机上。相较之下,MidJourney 工具的模型没有公开,而且主要是为图像生成设计的,因此无法用来生成逐帧动画。

动画也可能使用 Stable WarpFusion 来制作,这其中涉及到图像转图像的工作流程,通过一些扭变(置换)将底层的视频输入变成动画。视频作者:Sagans。
在每张生成的图像帧上逐渐进行参数插值,以得到过渡动画。这里的参数可能包括任何与模型相关的设定,比如文本 prompt 本身或底层的种子(隐空间游走)。

prompt 编辑法,即通过逐渐改变权重来创建动画过渡。这里使用了 Depth ControlNet 来保持手部整体形状的一致性。
通过图像到图像技术,将每张生成的图像帧作为输入来生成动画的下一帧。这样在参数和种子变化时也可以生成看起来相似的帧序列。这个过程通常由 Deforum 中的「去噪强度」或「强度调度」来控制。起始帧可以是已有的图片。
这是大多数使用 Stable Diffusion 的动画实现的一个核心组件,而 Stable Diffusion 是下列许多应用依赖的技术。这种技术很难平衡,并且很大程度上取决于使用的采样器(噪声调度器)。

逐渐变换每一帧生成图像,之后再将其作为 I2I 循环的输入。2D 变换对应于简单的平移、旋转和缩放。3D 技术则会想象一个在 3D 空间中移动的虚拟相机,这通常需要估计每帧生成图像的 3D 深度,然后根据想象中的相机运动来进行变形处理。

想必你已经看过这种无限放大的动画。它的视觉效果如此之棒,是因为其使用了 SD 来持续构建新细节。
运动合成的目标是「想象」后续生成帧之间的运动流,然后使用这个运动流来逐帧执行变形处理,从而基于 I2I 循环注入有机的运动。这通常需要依赖在视频的运动估计(光流)上训练的 AI 模型,只不过其关注的不是后续视频帧,而是后续生成帧(通过 I2I 循环),或是使用某种混合方法。
技术还包括图像修复和变形技术搭配使用、采用多个处理步骤或甚至捕获模型训练过程的快照等先进技术。举个例子,Deforum 有很多可供用户调控的地方。

使用 SD-CN Animation 制作,其使用了一种在生成帧之间产生幻觉运动的独特方法。起始图像只是作为起点,没有用途。
这类方法范围很广,做法是使用输入视频来混合和影响生成的序列。这些输入视频通常分为多个帧,作用通常是风格化现实视频。在现如今的风格化跳舞视频和表演热潮中,这类技术常被用于实现动漫造型和体格。但你可以使用任何东西作为输入,比如你自己动画的粗略一帧或任何杂乱抽象的录像。在模仿 pixilation 这种定格动画技术和替换动画技术方面,这类技术有广泛的可能性。
在每一帧,输入帧要么可以直接与生成图像混合,然后再输入回每个 I2I 循环,要么可以采用更高级的设定附加条件的做法,比如 ControlNet。

Deforum 搭配 ControlNet 条件化处理的混合模式,左图是原视频。遮掩和背景模糊是分开执行的,与这项技术无关。
「光流」是指视频中估计的运动,可通过每一帧上的运动向量表示,其指示了屏幕空间中每个像素的运动情况。当估计出变形工作流程中的源视频的光流后,就可以根据它对生成的帧执行变形,使得生成的纹理在对象或相机移动时也能「粘黏」在对象上。

Deforum 的混合模式支持这种技术搭配各种设置使用。为了得到闪动更少的结果,也会增加 cadence,使得变形的效果更好杏彩体育。遮掩和背景模糊是分开执行的,与这项技术无关。
通过变形工作流程完成的条件处理也可能直接关联 3D 数据,这可以跳过一个可能造成模糊的环节,直接在视频帧上完成处理。
举个例子,可以直接通过虚拟 3D 场景提供 openpose 或深度数据,而不是通过视频(或经过 CG 渲染的视频)估计这些数据。这允许采用最模块化和最可控的 3D 原生方法;尤其是组合了有助于时间一致性的方法时,效果更佳。

有一个广泛应用的工具也使用了该技术,其可简化并自动化用 Blender 生成直接适用于 ControlNet 的角色图像的过程。在这个示例中,ControlNet 使用手部骨架来生成 openpose、深度和法线贴图图像,最终得到最右侧的 SD 结果。(openpose 最终被舍弃了,因为事实证明它不适用于只有手部的情况。)
将所有这些技术结合起来,似乎有无尽的参数可以调整动画的生成结果(就像模块化的音频制作)。它要么可以通过关键帧进行「调度」并使用 Parseq 这样的工具绘制图形,要么可以与音频和音乐关联,得到许多随音频变化的动画。只需如此,你就能使用 Stable Diffusion 帮你跳舞了。
注:最好的情况是你有足够的优良硬件(即 GPU)在本地运行这些工具。如果没有,你也可以尝试运行在远程计算机上的、功能有限的免费服务,比如 Google Colab。不过,Google Colab 上的笔记本也可以运行在本地硬件上。
这类技术使用在运动视频上训练的视频生成 AI 模型,另外可以在神经网络层面上使用时间压缩来增强。
目前,这些模型有一个共同特征是它们仅能处理时间很短的视频片段(几秒),并受到 GPU 上可用视频内存的限制。但是,这方面的发展速度很快,并且可以用一些方法将多个生成结果拼接成更长的视频。
现今的这类模型得到的结果往往晃动很大、有明显的 AI 痕迹、显得古怪。就像是很久之前生成图像的 AI 模型一样。这个领域的发展落后一些,但进展很快,我个人认为在静态图像生成上取得的进展并不会同等比例地在视频生成方面重现,因为视频生成的难度要大得多。

我认为在这方面,动画和传统电影之间的界限很模糊。只要其结果还与现实有差异,那么我们就可以在一定程度上把它们看作是动画和视频艺术的一种怪异新流派。就目前而言,我认为大家还是别想着用这类技术做真实风格的电影了,只把它视为一种新形式的实验媒体即可。玩得开心哦!
理论上讲,这类技术有无限可能性 —— 只要你能将其描述出来(就像静态图像生成那样),就可能将其用于直播表演或生成任何超现实和风格化的内容。但从实践角度看,为了训练视频模型,收集多样化和足够大的数据集要难得多,因此仅靠文本来设定生成条件,很难用这些模型实现利基(niche)的美学风格。
使用这种方法,只能很宽松地控制创意工作。当与图像或视频条件化处理(即变形工作流程)组合使用时,这种技术就会强大得多。

很多视频生成工具都能让你以图像为条件生成视频。其做法可以是完全从你指定的图像开始生成,也可以将指定图像用作语义信息、构图和颜色的粗略参考。

类似于图像生成模型中的图像到图像过程,也有可能将输入视频的信息嵌入到视频模型中,再加上文本 prompt,让其生成(去噪)输出。
我并不理解这其中的具体过程,但似乎这个过程不仅能在逐帧层面上匹配输入视频片段(如同使用 Stable Diffusion 进行风格化处理),而且能在整体和运动层面上匹配。和图像到图像生成过程一样,这个过程受去噪强度控制。

如果运气好并且有合适的 prompt,你也可以输入视频来「启发」模型重新想象源视频中的运动,并以完全不同的形式将其呈现出来。使用 webui txt2vid 中的 Zeroscope 完成,使用了 vid2vid 模式。
注:最好的情况是你有足够的优良硬件(即 GPU)在本地运行这些工具。如果没有,你也可以尝试运行在远程计算机上的、功能有限的免费服务,比如 Google Colab,不过大多数免费或试用服务的功能都有限。
随着 AnimateDiff 的日益流行,出现了一个使用视频或「运动」压缩来增强已有图像扩散模型的新兴领域。相比于使用逐帧技术生成的结果,其生成的结果更相近于原生视频模型(如上面介绍的)。这种技术的优势是你还可以使用为 Stable Diffusion 等图像模型构建的工具,如社区创建的任何检查点模型、LoRA、ControlNet 以及条件化处理工具。
你甚至有可能通过 ControlNet 提供视频条件化处理,就像是使用逐帧技术一样。社区仍在积极实验这一技术。可用的技术有的来自静态图像模型(比如 prompt 遍历),也有的来自视频原生模型。
这种技术中的运动本身通常非常原始,只是在视频片段中松散地插入对象和流,这往往会将事物变形成模样。不过,这种技术有更好的时间一致性,而且仍处于起步阶段。当场景很抽象,没有具体物体时,这种方法能得到最好的结果。
大家都知道,这是一个流行迷因背后的技术。你可能看过一个相对静止的人物(相机可能在移动)只有脸动着说话,这多半是用到了 AI 人脸动画化和语音合成工具的组合方法。
这其中组合了多个技术步骤和组件。其源图像多半是使用图像生成 AI 制作的,但也可以使用任何带有人脸的图像。语音是根据文本生成的,并根据所选任务的音色进行了条件化处理。然后再使用另一个工具(或工具包中的某个模型)合成与音频唇形同步的人脸动画 —— 通常只生成图像中脸部和头部区域的运动。使用预训练的数字化身也能让身体动起来。

这是指为 3D 人物合成运动的技术。这类技术可以应用于 3D 动画电影、视频游戏或 3D 交互应用。正如图像和视频领域一样,新兴的 AI 工具让人可通过文本来描述人物的运动。此外,一些工具还能根据很少的关键姿势来构建运动或者在交互环境中实时动态地生成动画。

Nikita 的充满天才巧思的元人工智能电影预告片,其中将 AI 的运动学习过程展现成了一部滑稽幽默的有趣短片。
由于本文的关注重点是生成工具,因此没有包含自动化某些非创意任务的 AI 应用,比如 AI 驱动的运动跟踪、合成、打码等,例子包括 Move.ai 和 Wonder Dynamics。
从理论上讲,由于大型语言模型(LLM)在编程任务上表现出色,尤其是经过微调之后,那么我们就可以在制作动画的软件中让其编程和编写脚本。这就意味着按照常规工作流程制作动画时,能让 AI 从头到尾一直辅助。极端情况下,AI 能帮你完成一切工作,同时还能为后端流程分配适当的任务。
在实践中,你也能尝试这么做了!举个例子,Blender 配备了非常广泛的 Python API,允许通过代码操作该工具,因此现在已经有几个类似 ChatGPT 的辅助工具可用了。这个趋势不可避免。只要有代码,LLM 多半就会有用武之地。
注:还有一个即将推出的 ChatUSD—— 这是一个可以操作和管理 USD 的聊天机器人,这是由皮克斯最初创建的标准,用以统一和简化动画电影制作中的 3D 数据交换和并行化。目前没有更多相关消息了,但英伟达似乎很欢迎这项标准并在推动其成为各种 3D 内容的标准,而不只是电影。
终于完结了!内容很多,但我多半还是遗漏了一些东西。你觉得还有什么内容有待补充或还有什么相关工具值得提及,请在评论区与我们分享。